불과 2~3년 전, 우리나라에 TDD, 즉 테스트 주도 개발이 떠오르던 시기가 있었습니다. 그 이후 많은 개발자들이 테스트 코드를 작성하거나, 테스트 코드를 애플리케이션에 도입하려는 긍정적인 현상이 나타났던 것 같습니다. 하지만, 우리에게는 좀더 넓은 시야가 필요합니다. 우리는 이제 모든 서버를 클라우드 기반으로 배포합니다. 그중 많은 회사들은 쿠버네티스를 적극 도입하고 있습니다. 클라우드 네이티브와 분산 시스템은 이제 많은 엔지니어들의 관심거리이자 걱정거리가 된 것 같습니다. ‘만약 데이터 센터에 에어컨이 꺼져서 해당 region에 서버를 모두 이용하지 못하면 어떻게 될까요?[1]’. ‘데이터 센터에 불이 나버리면 어떻게 될까요?[2]’. 하다 못해 ‘일시적으로 네트워크를 이용하지 못한 상황이 되면 어떻게 될까요?’ 우리의 애플리케이션 테스트코드는 이런 혼돈(Chaos)를 대비하지 못합니다. 모든 Chaos(이하 카오스) 중 애플리케이션에서 발생하는 카오스는 약 10% 정도 밖에 되지 않습니다. 아래의 사진을 통해 확인할 수 있습니다.
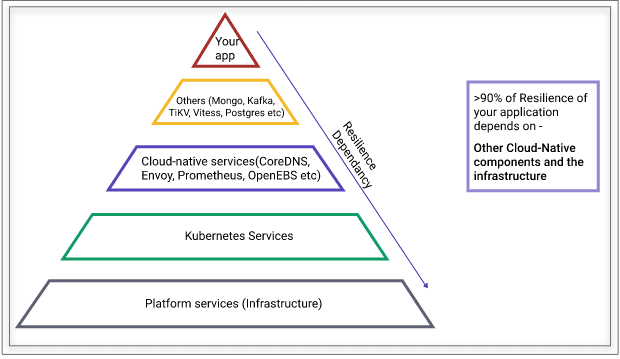
출처 : LitmusChaos Docs[3]
다른 모든 카오스는 애플리케이션 밖에 존재하는 데이터베이스, DNS 서버, 클라우드 제공업체 와 같은 곳에서 일어납니다. 엔트로피는 증가하는 방향으로 흐르기 때문에 이런 종류의 카오스는 언젠가 우리에게 찾아올 수 있습니다. 카오스 엔지니어링은 이런 막연한 절망을 엔지니어의 계획 안에서 통제할 수 있는 하나의 실험 정도로 만들어가는 엔지니어링 분야입니다. 하지만 막상 카오스 엔지니어링을 우리 회사에 도입하자니 장애물에 턱턱 막히곤 합니다. 최근 제가 기여하고 있는 오픈소스 카오스 엔지니어링 플랫폼인 LitmusChaos를 만들고 있는 Harness에서 ChaosCarnival2023을 개최하였습니다. AWS 의 Principal System Dev Engineer인 Adrian Hornsby가 ‘Climbing out of the Chasm - Unleashing the Potential of Chaos Engineering[4]‘라는 제목으로 키노트 발표를 하였습니다. 본 영상에서는 성공적으로 카오스 엔지니어링을 회사에 도입하기 위해 우리가 해야할 것들을 알려줍니다. 다소 오역이 있을 순 있으나 최대한 잘 요약해보겠습니다.
카오스 엔지니어링이란
카오스 엔지니어링은 특정 시스템에 대한 가설(hypothesis)을 만들고 부하(stress)를 주입한 후 결과를 관찰하는 엔지니어링의 한 분야입니다. 이후 관찰된 결과를 바탕으로 시스템의 성능을 향상시킵니다. 그렇기 때문에 이 과정은 아래 그림처럼 끊임 없이 순환됩니다.
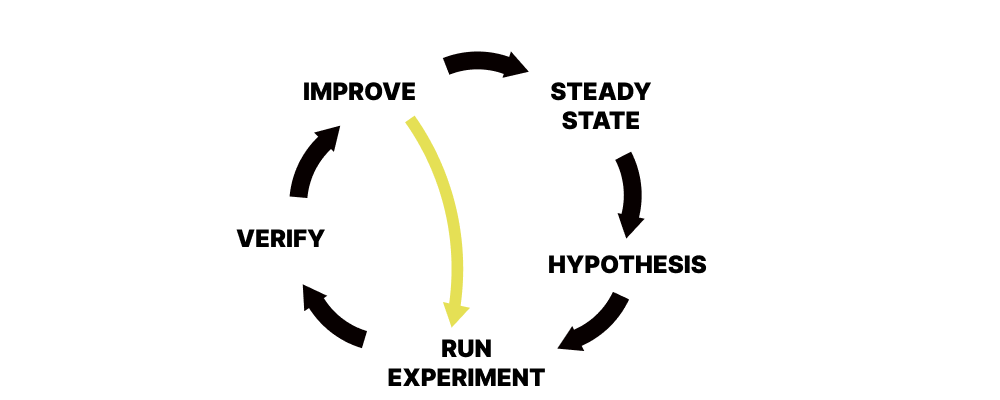
계속해서 새로운 가설을 만들고 이를 통해 시스템을 발전시킵니다. 카오스 엔지니어링은 우리 시스템이 회복성(resilience) 있고 성능이 좋은 시스템을 구축할 수 있게 해줍니다. 또한 우리가 모니터링이나 알람 설정등에서 발견하지 못했던 이슈들을 밝혀내기도 합니다.
다음과 같이 실제 회사들에서 서비스를 운영하는데 있어 다운타임(downtime)으로 인해 발생하는 비용은 엄청납니다.
- annual fortune 1000 application downtime costs(IDC) : 1.25 - 2.5B
- Average cost/hour of downtime(Ponemon Institude) : 474K
- cost/hout of a critical application failure(IDC) : 500K - 1M
- average cost/hour of an infrastructure failure(IDC) : 100K
카오스 엔지니어링을 도입한다면 여러분의 비즈니스를 비용 효율적으로 운영하실 수 있을 것입니다.
카오스 엔지니어링을 정의 하자면..
한 회사의 컨퍼런스에 참여한 적이 있습니다. 그곳의 많은 엔지니어들은 분산 시스템, 회복성 등등.. 수많은 경험을 지니고 있었습니다. 엔지니어의 이러한 능력(quality)는 하루 아침에 만들어지는 것이 아닙니다. 이런 능력은 수많은 상황을 마주하고 개선을 위해 기꺼이 자신의 서비스를 노출(exposure)시킬 수 있어야 합니다. 이러한 활동은 굉장히 많은 시간이 필요합니다. 상황에 노출되고 이것에 시간을 소비하는 것을 우리는 경험이라고 합니다. 과학은 우리가 부정적인(negative) 경험(실패 등)을 할때 더 많은 배움을 얻는다고 말합니다. 그들이 뛰어난 엔지니어가 되었다는 것은 그들은 이미 수많은 문제에 직면했을 것이라는 걸 의미합니다. 저(강연자)의 경우는 프로덕션 환경의 데이터베이스를 날린 적이 있습니다. 이때 많이 배우고 엔지니어로써 성장할 수 있던 것 같습니다.
하지만 의아한 부분이 있었습니다. 제가 방문했던 회사는 역사가 길지 않았습니다. 그럼에도 어떻게 이런 성숙한 엔지니어들을 많이 배출할 수 있었을 까요? 이 회사에서는 카오스 엔지니어링을 적극 수용했습니다. 엔지니어들은 프로덕션 환경에서의 고통스러운 실패를 마주하길 기다리지 않았습니다. 대신 통제 가능한 실패들을 카오스 엔지니어링을 통해 해결해나갔습니다.카오스 엔지니어링은 운영체제에 대한 지식 뿐 아니라 시스템의 장애를 복구할 수 있는 방법을 배울 수 있게 합니다. 따라서 카오스 엔지니어링을 이렇게 정의하고 싶습니다.
Chaos engineering is a compression algorithm for experience.
시스템을 테스트 하는 방법
시스템을 테스트하는 방법은 크게 다섯가지입니다.
- Ad-hoc : 대게는 형식적이지 않고 시스템의 핸덤한 부분을 테스트합니다. 그렇기 때문에 문서로 정리하는경우도 드뭅니다. 엔지니어의 역량에 따라 테스트 효율성이 크게 달라집니다.
- Game days : 특정한 날짜에 팀을 구성하여 하나의 사건(카오스)를 가정하고 진행합니다(국내에서는 AWS GameDay가 있습니다[5]). 진행 비용이 비싼 단점이 있습니다.
- CI / CD 안에서 테스트 : 애플리케이션 초기 배포시 실행하는 테스트 방식입니다. 특정 플랫폼이나 운영체제에 종속되지 않는 장점이 있습니다.
- canary (a/b) : 새로운 버전의 애플리케이션과 기존 버전을 비교하는 방식입니다. 네트워크를 적절히 분산시켜 흘려보내는 방식으로 진행합니다.
- continuos : 프로덕션 환경에서의 테스팅 플랫폼입니다. 지속적으로 카오스를 주입하는 방식입니다.
현재 대부분의 회사는 ad-hoc과 game days 정도만 사용할 것입니다. 즉, 우리는 결과를 모두 만들어둔 후에 테스팅을 한다는 것입니다. 테스팅 후 설계에 대한 변경사항이 크다면 우리는 두번 일하게 됩니다. 우리는 앞으로 Shift Left(개발 초기부터 테스팅, 카오스 엔지니어링을 해야 한다는 의미)[6]접근 방식을 사용해야 합니다.
카오스 엔지니어링이 회사에 적용되기 어려운 이유
제프리 무어의 캐즘 마케팅[7]이라는 도서를 소개하고 싶습니다. 책에서는 기술이 사회에 적용되는 과정을 5단계로 분류 합니다. 아래 그래프는 초반의 혁신가(innovator)와 초기 사용자(early adoptor)를 넘어 대중들에게 기술이 적용되어야 함을 나타냅니다.
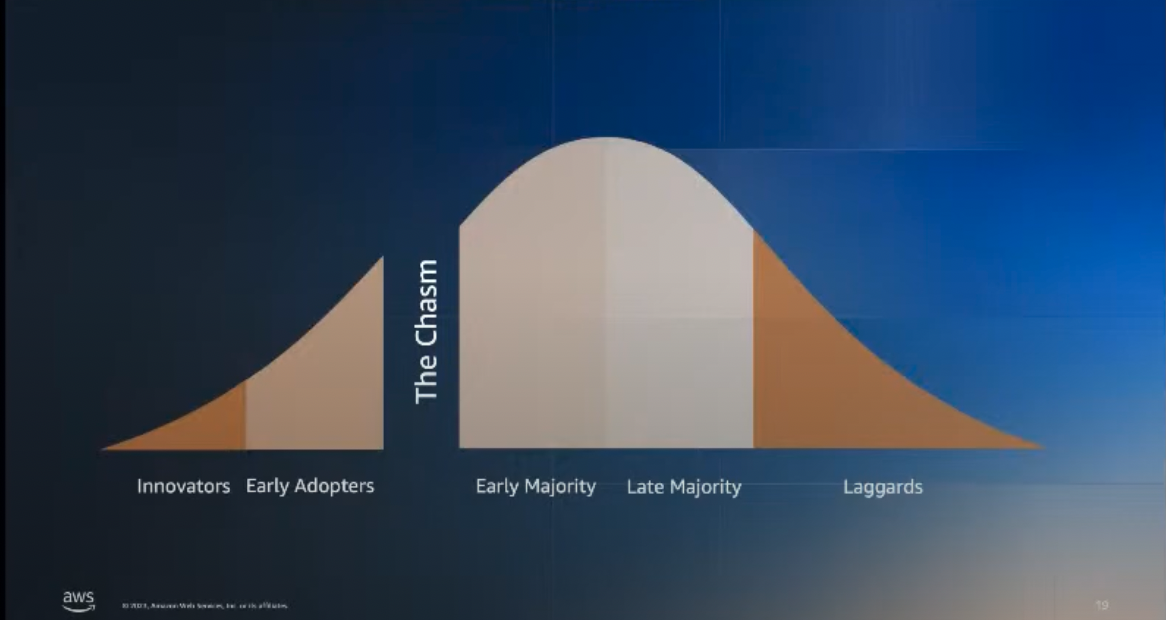
출처 : Climbing out of the Chasm - Unleashing the Potential of Chaos Engineering[4]
기술이 소수를 넘어 대중에게 보급되기 전까지 일종의 chasm(단절)이 존재합니다. 이 chasm을 벗어나기 위해 마케팅 전략을 바꿔야할 수도 있고 심지어는 기술 자체를 변경해야할 수도 있습니다. 이런 과정을 crossing the chasm 이라고 합니다. 이 이론은 마케팅 시장에만 국한되지 않습니다. 이 이론은 기술의 확산에도 동일하게 적용됩니다. 이 이론은 왜 몇몇의 팀들이 새로운 컨셉과 아이디어를 다른사람보다 먼저 적용하는지 설명해줍니다. 심지어는 같은 회사 내에서도 기술의 확산 속도가 다릅니다. 이는 많은 회사들이 chaos engineering chasm 에서 벗어나지 못했음을 의미합니다. 몇몇의 팀은 카오스 엔지니어를 수월하게 시작했을 것입니다. 하지만 회사 전체에 카오스엔지니어를 적용하려면 스탠다드한 규율을 정의해야하는데 이 과정에서 어려움이 있을 것입니다. 만약 여러분의 팀 만이 카오스 엔지니어링을 잘 활용하고 있다면, 그것은 여러분 팀 안에 early adatoper가 있기 때문일 것입니다. 그렇다면 이 chasm을 어떻게 해쳐나가야 할까요? 어떻게 하면 카오스 엔지니어링을 전사에 적용시킬 수 있을까요? 카오스 엔지니어링이 회사의 비즈니스에 도움을 준다고 어떻게 확신할 수 있을까요?
Crossing the chasm
이러한 chasm을 넘어 성공적으로 카오스 엔지니어링을 도입하기 위해서는 어떻게 해야할까요? 저는 다음의 다섯가지를 제시합니다.
- Understanding the Why
- Setting goals
- Getting started
- Reinforcing Mechanisms
- Anything is better than nothing
하나하나 알아보겠습니다.
Understanding the Why
‘왜’라는 질문으로 시작해 보세요. 스타트 위드 와이(Start With Why)[8] 라는 도서에서는 의사 결정시 사용 되는 3단계로 구성된 골든 서클을 보여줍니다.
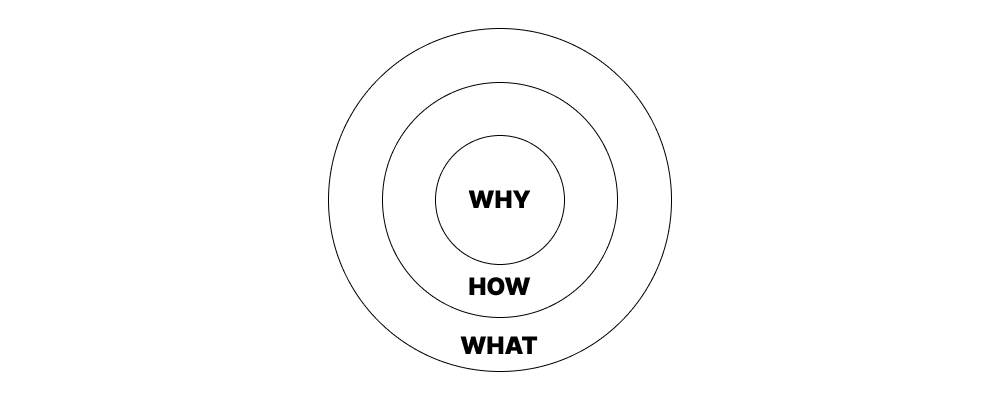
- Why는 비즈니스가 애초에 왜 존재해야하는지에 대한 core belief입니다.
- How는 어떻게 비즈니스가 core belief를 이행하는 지를 의미합니다.
- What은 회사가 core belief를 실천하기 위해 무엇을 하는지를 의미합니다.
저자에 따르면 ‘왜’야말로 우리가 우리가 해야하는 일에 대한 당위성을 제시해줍니다. 이를 통해 더 많은 성취를 이룰 수 있습니다. 이 이야기는 카오스 엔지니어링에도 동일하게 적용됩니다. 우리가 만약 타인에게 카오스 엔지니어링을 도입해야한다고 납득시켜야 할때, 우리는 대게 ‘무엇을’, ‘어떻게’ 카오스 엔지니어링 할지에 대해 이야기합니다. 우리는 ‘왜’ 카오스 엔지니어링을 해야하는지 이야기하지 않는데, 왜냐하면 우리는 대게 innovator 나 ealy adopter가 아닌 일반적인 엔지니어 이기 때문입니다. 따라서 우리는 다른 모든 논의를 하기 전에 왜 카오스엔지니어링이 비즈니스에 도입해야하는지 충분히 납득시킬 수 있어야 합니다. 가령 우리가 겪는 다운 타임문제가 왜 생기고 이것을 카오스 엔지니어링을 도입함으로써 어떤 긍정적인 효과를 낼 수 있는지 이야기하는 것이 하나의 방법이 될 수 있습니다.
Setting goals
‘왜’ 카오스엔지니어링을 해야하는지 이해하였다면, 이제는 목표를 정할 시간입니다. 목표를 정하는 것은 동기부여에 도움이 되며, 특히 어려운 목표일 수록 더욱 몰입하여 일을 완수할 수 있습니다. 카오스 엔지니어링에서의 목표를 정하지 않는다면, 그자체로 카오스 엔지니어링 도입에 걸림돌이 될 수 있습니다. 또한 정확한 목표가 없으면 무의미한 지출을 할 가능성이 높습니다. 목표는 다음과 같이 여러 가지가 있을 수 있습니다.
- user experience
- service recovery
- adoption
- experiment
- metrics
- event
- launch
- verify configurations
카오스 엔지니어링을 성공적으로 도입한 회사들은 공통적으로 ‘top-down’방식의 목표를 세웠습니다. 제가 바왔던 바로는 상위 결정권자의 리더십으로 세운 목표가 장기적으로 카오스 엔지니어링을 지속적으로 유지하는데 가장 좋은 방법이었습니다. 특히 이러한 리더쉽으로 세운 목표들은 월마다, 분기마다 관리되어 지속될 수 있었습니다. 반대로 리더십의 부재로 팀 단위에서 목표를 설정한 것은 종종 난관에 부딪히게 됩니다.
목표는 거창하지 않아도 됩니다. 제가 속한 AWS의 예시를 들어보겠습니다.
첫번째 예시는 configuration check를 목표로 설정하는 것입니다. 2020년 3월에 프라임 비디오라는 회사에서 프라인 비디오 프로파일을 런칭했습니다[9]. 해당 서비스는 기본적으로 유저의 추천 항목들과 시청시간, 본 영상 목록을 제공합니다. 또한 여러 다른 서비스를 ec2 위에 제공합니다. 이 서비스들은 분산 시스템의 일부이며 내부적으로 aws의 다른 서비스들을 네트워크를 통해 호출했습니다. 그래서 timeout 테스트, retry 테스트, 서킷브레이커 유효성 검증등이 모두 중요했습니다. 또한 api 시간초과가 특정 제한을 넘지 않는 것이 중요한 목표 중 하나였습니다. 그래서 프라임 비디오에서는 오픈소스 카오스 엔지니어링 툴을 이용해 설정한 configuration 대로 분산시스템이 잘 동작하는지 테스트들을 진행했습니다. 그 결과 여러 버그들을 조기에 발견할 수 있었습니다.
두번째 예시는 service recovery(서비스 복구)를 목표로 설정하는 것입니다. aws의 람다 팀은 availability zone중 하나가 완전히 사용 불가할 때 5분안에 다른 zone에 서비스를 복구하는 것을 목표로 삼았습니다[10]. 이 목표를 가지고 람다팀에서는 사용자의 트래픽을 안전한 지역으로 옮기는 자동화툴을 개발하였는데 이를 availabilty zone evacuation이라고 합니다. 이를 검증하기 위해 람다팀에서는 카오스 엔지니어링을 사용하였습니다.
세번째 예시로는 user experience를 목표로 설정하는 것입니다. 이는 amazon search의 예에서 볼 수 있습니다[11]. 아마존 서치는 아마존 홈페이지의 검색을 담당합니다. 아마존 프라임 데이에 대비하여 사용자가 몰려도 안정적으로 서비스할 수 있게 하기 위해 카오스 엔지니어링을 도입하여 설계를 수정하고 검증해 나갔습니다.
마지막으로 metric(성능 지표)가 목표로 설정될 수 있습니다. 이는 논쟁거리긴 합니다. resilience 스코어는 해당 시스템이 얼마나 베스트 프렉티스를 잘 이행했는지 나타냅니다. 이 점수는 resilience 정책이나 표준 알람 절차, 몇가지 테스트나 카오스 실험 등으로 매겨질 수 있습니다. 이 점수는 서비스 오너가 더 resilient하게 시스템을 만들게 유도할 수 있습니다. 보통 낮을 수록 좋은 resilience를 가지고 있음을 의미합니다. 하지만 회사가 메트릭에 너무 의존하거나 메트릭변화로 금전적인 인센티브를 줄 경우 본래의 목적에서 벗어날 수 있음을 알아야 합니다(엔지니어들은 시스템을 더 resilience하게 만드는 것이 아닌 점수를 좋게 만드는 것에 초점을 맞추게 됩니다).
Getting started
목표를 정한 이후, 카오스 엔지니어링을 처음 도입해야 한다면, 무엇부터 시작해야할까요? 어떤 가설을 설정해야할까요? 등의 질문을 받습니다. 저는 이런분들에게 이런 질문을 합니다.
“What are you worrying about”
팀에서 어떤한 것을 걱정하고 있다는 것은 대게는 직관으로부터 시작되는데 이 직관이 들어맞는 경우가 생각보다 많습니다. 만약 팀에서 몇명이 공통적으로 걱정하고 있는것이 있다면 그것을 우선순위로 두어야 합니다. 그리고 실험에 대한 설계시 해당내용들을 참고해야 합니다. 직관에 대해 시간을 쏟는 것은 절대 시간을 낭비하는 것이 아닙니다. 하지만 우리는 ‘Dogs Not Barking’ 문제에 대해 생각해볼 필요가 있습니다.
셜록홈즈에 나온 짧은 에피소드 입니다.
- 그레고리 형사 : 내 흥미를 끌만한 사건이 이곳에 있었나요?
- 셜록홈즈 : 지난 밤에 개의 행동이 흥미로웠습니다.
- 그레고리 형사 : 그렇지만 개는 지난 밤에 전혀 짓지 않았잔아요
- 셜록홈즈 : 그 점이 흥미롭다는 것입니다.
이 짧은 이야기의 교훈은 우리가 보여지지 않는 것에 관심을 가져야 한다는 것을 의미합니다. 보이는 것 만큼 보이지 않는 것도 중요합니다.
두번째 질문은 다음과 같습니다.
“What are you not worrying about”
이 질문은 여러분들의 편향이나 과한 믿음에 태클질을 합니다. 예컨대 ‘우리 시스템은 절대 실패하지 않아 그래서 테스트도 필요없어’라고 하는 것은 보통 시스템이 실패를 하는지 조차도 모르는 경우처럼 말이죠. 왜냐하면 충분치 못한 모니터링이나 알람 혹은 단지 잘 작동하지 못했을 수도 있습니다. 개가 짓지 않은 것 처럼 말이죠.
카오스 엔지니어링을 시작할 수 있는 세번째 방법은 먼저 장애의 구조를 살펴보는 것입니다.
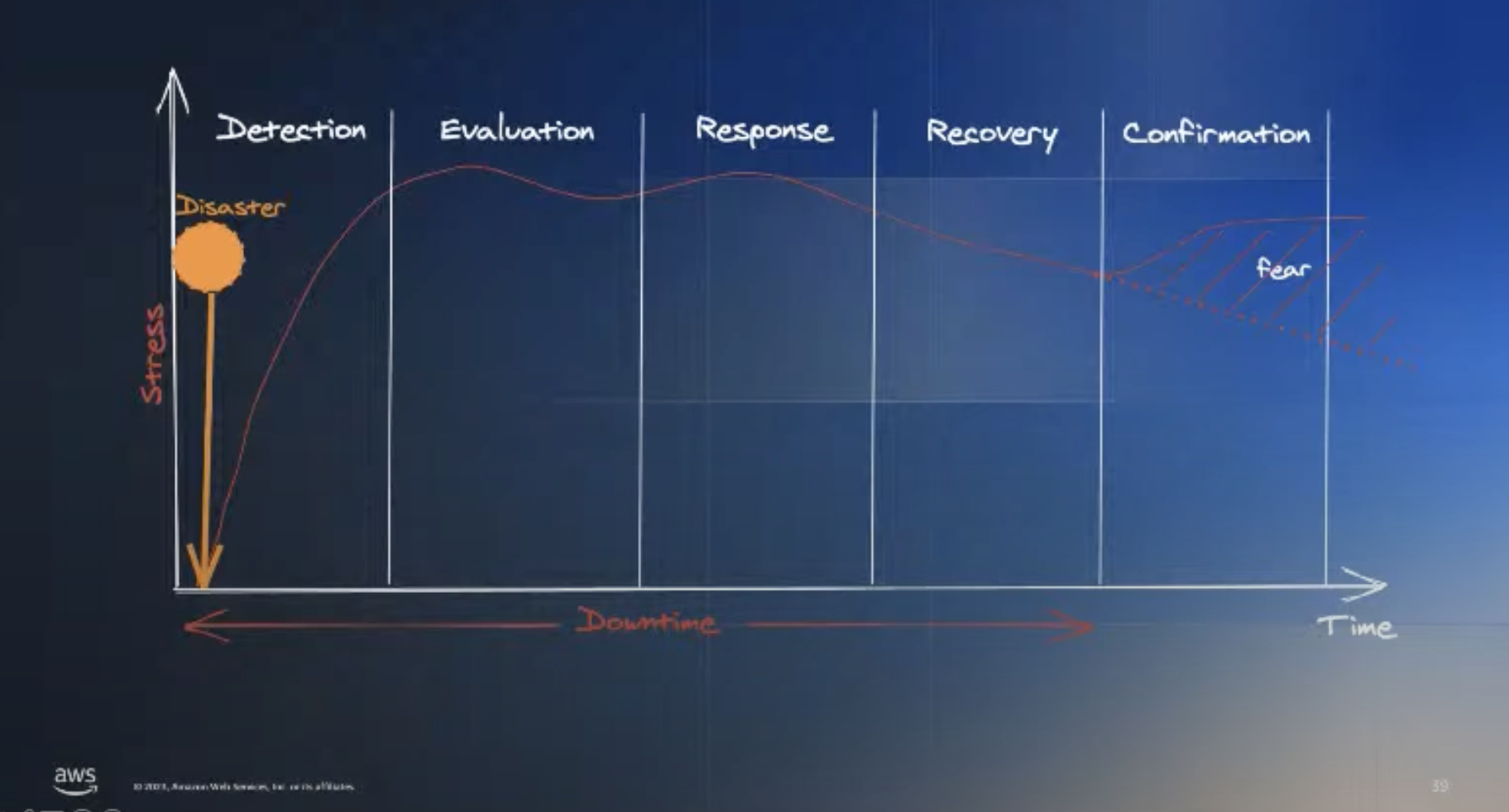
출처 : Climbing out of the Chasm - Unleashing the Potential of Chaos Engineering[4]
만약 장애가 발생했다면, 장애를 빠르게 복구할수 있는 능력이 중요해지게 됩니다. 이를 위해서는 많은 연습이 필요합니다. 보통 한 회사에는 수많은 서비스들이 엮여 있기 때문에 서비스간 중요도가 다르고 완전한 복구도 어려울 수 있습니다. 예컨대 이메일을 제공해주는 회사라면, 이메일의 송수신이 가장 중요한 서비스가 될 것이고 나머지는 덜 중요한 것이 될것입니다.
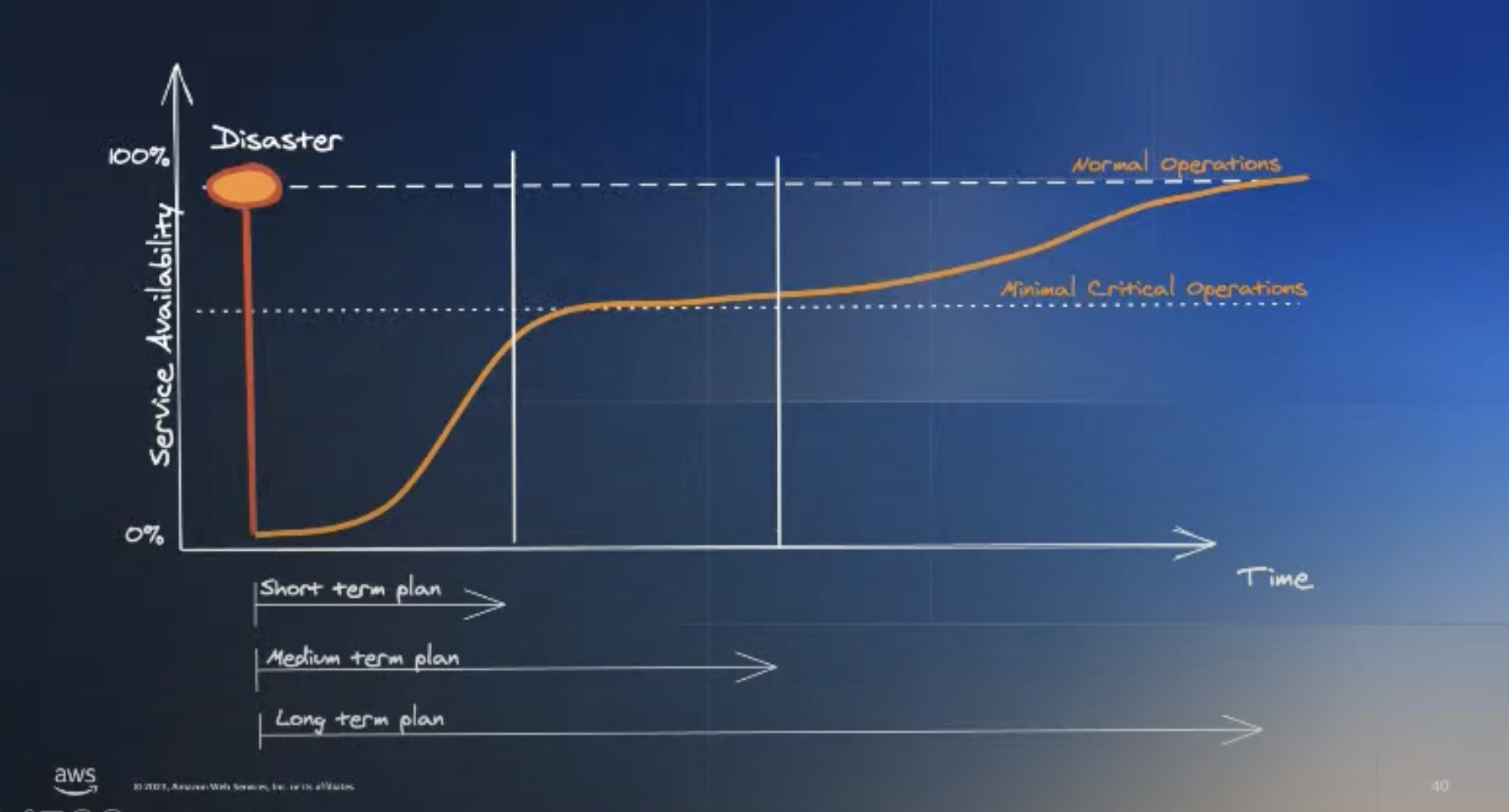
출처 : Climbing out of the Chasm - Unleashing the Potential of Chaos Engineering[4]
각 서비스는 다른 중요도를 가지고 있으므로 장애 발생 시 이 중요도를 파악하는 것은 복구 우선순위를 정하는데 좋은 영향을 줄 것입니다. 따라서 다음 표와 같이 우선순위에 따라 short, mid. long 텀 플랜을 세우고 중요도에 따라 배치하는 것을 추천합니다.
reinforcing Mechanisms
AWS 에서는 operational readiness review[12] 를 도입하였습니다. 정기적으로 서비스를 평가하여 시스템의 개선점을 찾습니다. 이를 통해 시스템의 blind 스팟을 찾을 수 있고 여러 이슈들을 확인할 수 있습니다.
Anything is better than nothing
우리는 인간이기 때문에 강연자가 멋지게 강연한 강연을 참고하여 정확하게 카오스 엔지니어링을 도입하고 싶어합니다. 강연을 하는 강연자들은 때로 별 무리없이 카오스엔지니어링을 한번에 적용한 것 처럼 보이죠. 하지만 모두가 고군분투합니다. 여러분들이 최고라고 여기는 회사들도 고군분투합니다. 심지어는 회사의 모든 조직원이 카오스 엔지니어링을 도입한 것도 아닙니다. 여러분들은 생각보다 뒤쳐지지 않았습니다.
‘100% of the winners tired’
지금 시작하는 것이 완벽한 행동이라고 할 수는 없지만 여러분들이 먼저 시작하여 캐즘을 넘음으로써 다른사람이 따라올 수 있게 하셨으면 합니다. 마지막으로, 모든 시스템은 유니크 합니다. 따라서 여러분이 한 곳에서 적용한 패턴이 다른곳에서는 유효하지 않을 수 있습니다. 우리가 만든 기술이 성공적으로 운영이 되려면 3가지 조건이 필요합니다. 첫번째는 올바른 문화이고 두번째는 좋은 tool이며 마지막은 완벽한 프로세스입니다. 카오스 엔지니어링은 기술에 집중합니다. tool에만 매몰되지 않으시길 바랍니다.
Reference
[1] AWS 장애에 당황한 고객사…쿠키런 킹덤, LOL 한때 먹통
[2] SK C&C 데이터센터 화재…왜 네이버는 되고, 카카오는 안될까
[3] LitmusChaos Docs
[4] Climbing out of the Chasm - Unleashing the Potential of Chaos Engineering
[6] Shift Left
[7] 제프리 무어의 캐즘 마케팅
[9] Building resilient services at Prime Video with chaos engineering
[10] AWS Lambda: Resilience under-the-hood
[11] Reliable scalability: How Amazon.com scales in the cloud